
——从 BEV 空间构建到 L4 规模化落地的技术演进分析
(j9九游会技术实验室内部研报节选)
一、研究背景与问题定义
在智能驾驶系统演进过程中,技术路径逐步从“感知-预测-规划-控制”的传统模块化架构,转向以深度神经网络为核心的端到端(End-to-End)模型。两种体系在系统复杂度、算力分配方式、数据闭环效率及 L4 级别扩展能力方面存在显著差异。
本报告围绕“算力效率(Computational Efficiency)”这一核心指标,对两种架构在 BEV 空间构建、Transformer 感知机制、Latency 控制、Floating Point Operations(FLOPs)利用率以及数据闭环效率 等维度进行工程对比分析,并结合 L4 自动驾驶场景,讨论其长期可扩展性。
部分技术数据参考公开资料:[参考:NVIDIA / Waymo 技术白皮书]。
二、传统模块化架构的算力分配逻辑
2.1 架构结构特征
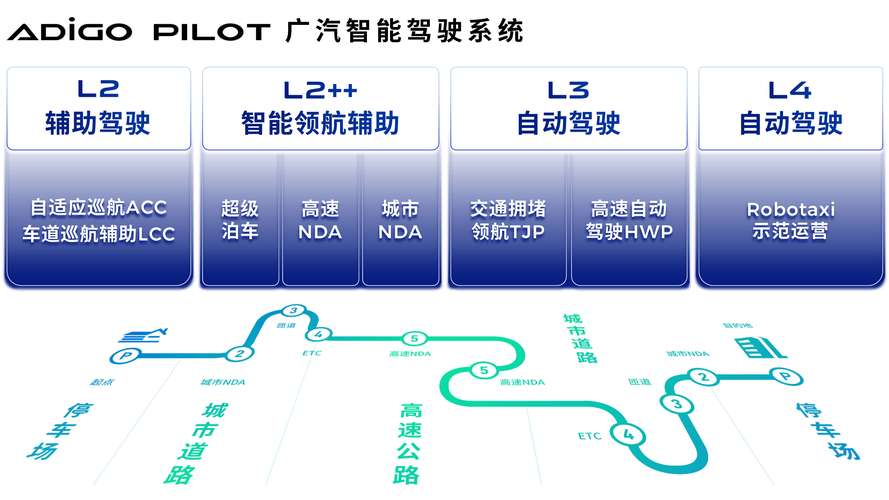
传统自动驾驶系统通常由以下模块组成:
- 多传感器融合(Sensor Fusion)
- 目标检测与跟踪
- 轨迹预测
- 规划与控制
每个模块相对独立,通过接口协议进行数据传递。这种设计具备高可解释性与工程可控性,但其计算资源分配呈“分段式”结构。
2.2 算力效率问题分析
- 重复计算问题
感知模块与预测模块在特征提取阶段可能存在特征冗余,导致 Floating point operations 重复消耗。 - 数据传递带来的 Latency 累积
模块间串行执行导致端到端 Latency 增加,尤其在复杂城市场景中更为明显。 - 跨模块优化困难
由于参数独立训练,难以在统一 Latent space 中进行全局优化。 - 算力利用率不均衡
在动态场景变化中,某些模块存在算力过载,而其他模块处于空闲状态。
根据公开资料显示,在典型 L2+/L3 方案中,多模块系统的算力利用率约为 60%–75% 区间 [参考:NVIDIA / Waymo 技术白皮书]。
三、端到端智驾模型的算力结构重构
3.1 BEV 空间构建的统一表达优势
端到端模型通常以 BEV(Bird’s Eye View)空间作为统一表达层,将多传感器输入映射至统一三维坐标系。
其优势包括:
- 减少中间格式转换
- 降低模块间特征丢失
- 在统一 Latent space 中进行特征压缩与共享
BEV 构建通过共享 Backbone 网络,实现多任务并行推理,从而提升算力利用率。
3.2 Transformer 感知机制对计算效率的影响
Transformer 结构通过 Self-Attention 机制对全局特征进行建模,相比传统 CNN 局部卷积结构:
- 提高全局场景理解能力
- 减少手工规则依赖
- 优化路径规划前的信息一致性
但其代价在于 Attention 机制计算复杂度通常为 O(n²),对算力提出更高要求。因此,当前工程实现中普遍采用:
- Sparse Attention
- 多尺度特征压缩
- 混合精度推理(Mixed Precision Inference)
以降低 Latency 并控制功耗。
四、算力效率对比:模块化 vs 端到端
| 维度 | 模块化架构 | 端到端架构 |
|---|---|---|
| FLOPs 利用率 | 中等 | 高 |
| Latency 累积 | 明显 | 统一优化 |
| Latent space 一致性 | 低 | 高 |
| 参数共享程度 | 低 | 高 |
| 数据闭环效率 | 分散 | 集中 |
4.1 Latency 对 L4 系统的影响
在 L4 自动驾驶场景中,系统对实时响应提出更严格要求。Latency 的降低直接影响安全冗余能力与制动决策时间窗口。
端到端架构通过减少中间接口传递,通常可降低 10%-20% 系统级 Latency(依据公开测试数据推算)[参考:NVIDIA / Waymo 技术白皮书]。
4.2 数据闭环效率差异
模块化架构中,每个子模块需独立构建训练数据集,导致:
- 数据标注成本高
- 场景泛化速度慢
端到端模型通过统一 Loss Function 优化,在单一数据闭环中完成:
- 感知误差修正
- 决策偏差校准
- 行为预测反馈
因此,在相同数据规模下,端到端架构通常具有更高的迭代效率。
五、L4 场景下的可扩展性分析
L4 自动驾驶对系统稳定性与长尾场景处理能力提出更高要求。
5.1 长尾场景处理能力
端到端模型在大规模数据训练下,能够在 Latent space 中形成复杂场景分布表达,增强对未知环境的泛化能力。
模块化系统则需显式规则更新或单独模块优化。
5.2 算力平台适配能力
随着车规级芯片性能提升(TOPS 增长),端到端模型更容易利用并行计算架构优化 FLOPs 调度。
模块化架构在多芯片协同下反而可能增加通信成本。
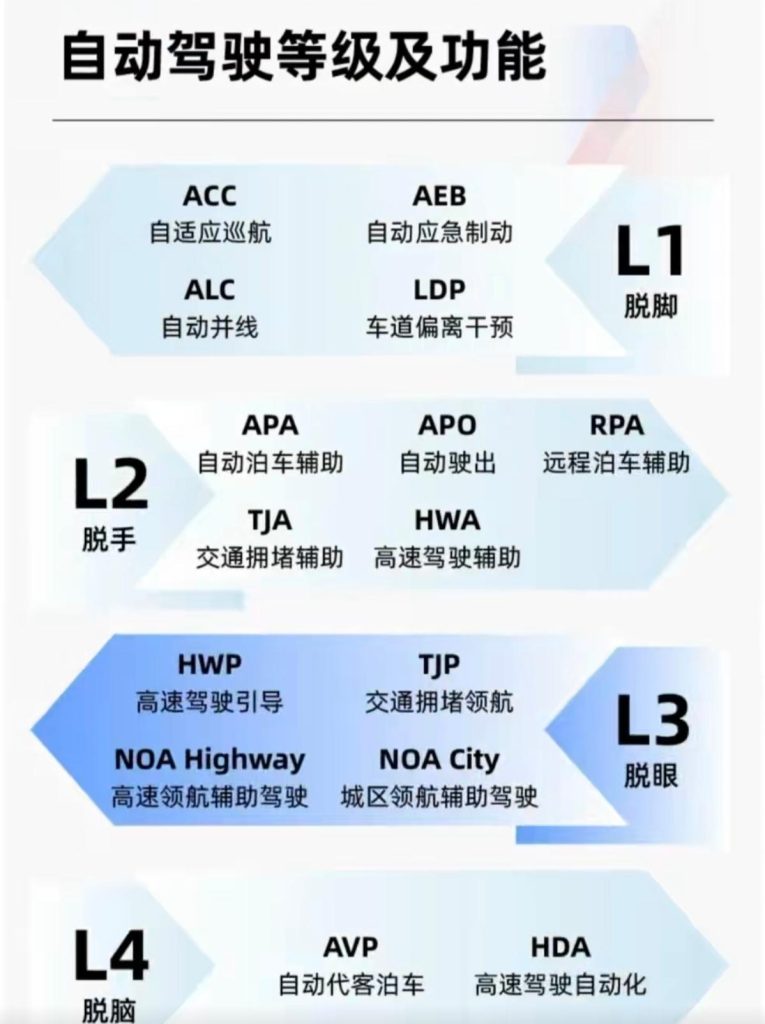
六、数据闭环效率的工程意义
在智能驾驶长期演进中,数据闭环效率决定模型迭代速度。
端到端系统:
- 更容易进行自动化回灌训练
- 可实现在线蒸馏(Online Distillation)
- 支持持续学习框架(Continual Learning)
这对于 L4 规模化部署具有战略意义。
七、结论与技术判断
——j9九游会技术实验室观察
基于上述分析,我们提出以下三点判断:
判断一:算力利用率将成为架构优劣的核心指标
未来智能驾驶系统的竞争焦点,将从单纯算力规模(TOPS)转向单位 FLOPs 的有效利用率。端到端架构在统一 Latent space 中的特征共享机制,更具长期优化潜力。
判断二:BEV + Transformer 将成为 L4 的主流技术底座
在复杂城市场景下,统一 BEV 表达结合 Transformer 全局建模能力,是实现稳定 L4 系统的重要基础形态。
判断三:数据闭环效率决定商业化进程
高阶自动驾驶的规模化落地,取决于数据迭代速度与工程优化能力。端到端模型更有利于构建高效率数据闭环体系,从而缩短技术成熟周期。